
错别字,咋就成了 AI 时代的活人感
错别字,咋就成了 AI 时代的活人感如今想写出一篇结构严密、用词专业的文章已经不算难事,只需要敲几个 prompt 生成式 AI 就能瞬间给你一篇成千上万字的文章。布鲁金斯学会去年的一项调查显示,拥有学士学位的成年人中有 35% 的人在工作中使用 AI 来撰写或编辑文档。
来自主题: AI资讯
9690 点击 2026-05-24 10:23
 搜索
搜索
如今想写出一篇结构严密、用词专业的文章已经不算难事,只需要敲几个 prompt 生成式 AI 就能瞬间给你一篇成千上万字的文章。布鲁金斯学会去年的一项调查显示,拥有学士学位的成年人中有 35% 的人在工作中使用 AI 来撰写或编辑文档。

当文字、图像、视频已经先后被生成式 AI 重写,3D 很可能就是下一站。
在生成式 AI 领域,视觉分词器(Visual Tokenizer)通常采用固定压缩率 —— 无论是单调的监控画面,还是复杂的动作大片,都被切分为等量的 Token。这种 "一刀切" 的做法不仅会造成巨大的计算冗余,也产生了 “信息量” 不同的 Token,不利于下游理解生成任务处理。

随着生成式 AI 迈入万亿参数时代,大语言模型(LLM)的推理与部署面临着前所未有的“显存墙”挑战。如何在超节点(SuperNode)复杂的异构存储架构下,实现海量张量的高效管理和调度,已成为大模型落地的胜负手。

在生成式 AI 浪潮中,文生图技术已实现跨越式发展,在视觉呈现上达到了前所未有的高度。然而,在生成图像中准确合成拼写正确、结构规范且风格协调的文字 —— 视觉文本渲染(Visual Text Rendering, VTR),至今仍是该领域尚未攻克的核心难题。
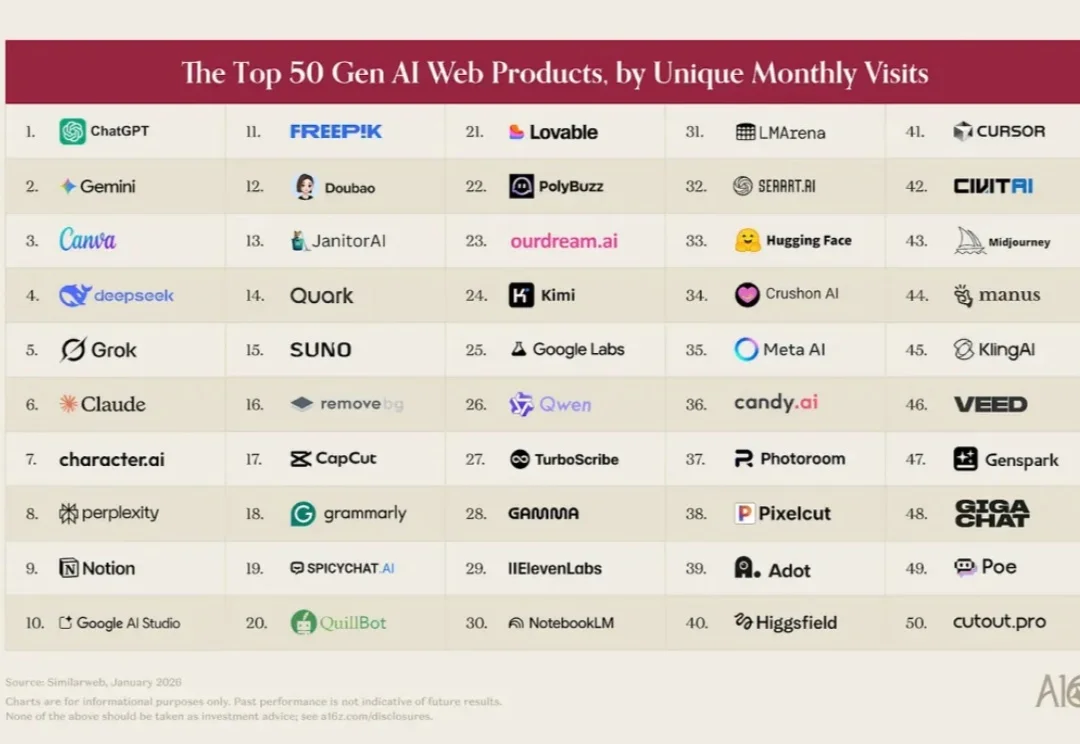
三年前,我们发布了这份榜单的第一版,目标很简单:找出哪些生成式 AI 产品真正被主流消费者使用。在当时,「AI 原生」公司和其他公司之间的界限很清晰。ChatGPT、Midjourney 和 Character.AI 都是围绕基础模型从零构建的产品,而软件行业的其他玩家还在摸索这项技术该怎么用。
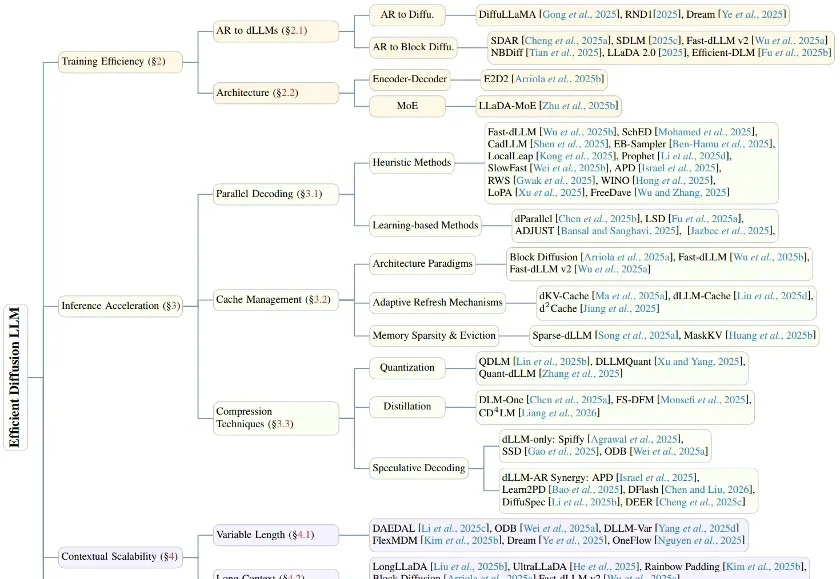
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。
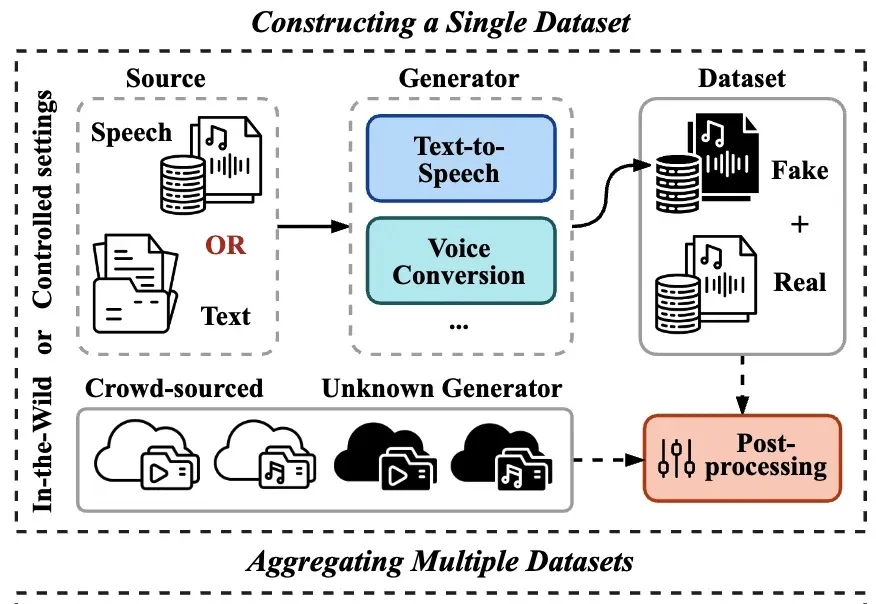
在生成式 AI 技术日新月异的背景下,合成语音的逼真度已达到真假难辨的水平,随之而来的语音欺诈与信息伪造风险也愈演愈烈。作为应对手段,语音鉴伪技术已成为信息安全领域的研究重心。

进入 2025 年,生成式 AI 正在从“概念验证”走向“规模化落地”,技术与应用的节奏明显加快。这个趋势在 Y Combinator 的 Demo Day 上体现得尤为清晰:在最新的 F25 批次中,AI 公司占比高达 53%(83 家 / 156 家),而在 2021 年的 W21 批次,这一数字仅为 12%。
在生成式 AI 的新时代,人们一直在讨论它会不会颠覆教育、改变编程、重塑工作方式——但你可能没想到:现在连 6 岁的小孩都能通过AI 变成“侵权生成器”了。